Ya sabeis, estais rellenando un formulario en una de esas webs de la administración con una pegatina que indica que es compatible con Netscape y se ve mejor con Windows XP, le dais a enviar, o se cuelga, o se pasa cualquier cosa y se pierden todos los datos introducidos. Eso no nos puede pasar a nosotros
Vamos a hacer un script para guardar todos los datos introducidos ante cualquier eventualidad. Para marcar que campos queremos almacenar, añadiremos el atributo “data-memo” a cada elemento del formulario
Empezamos linkando un evento “onbeforeunload” que se ejecutará cuando la pagina vaya a descargarse, por navegar a otro sitio o cerrar el navegador.
window.addEventListener('beforeunload', function() {
save()
});Definimos la funcion save, creamos un objeto donde guardar la informacion, y hacemos un query por una parte a los campos que no sean checkbox ni radio (o sea, los select, text, etc. de los que guardaremos su id y valor en el objeto memo.fields) y por otro lado, los input radio y checkbox (de los que guardaremos los id de los que estén marcados en un simple array memo.clicks ). Despues, almacenamos todos los datos en un local storage
function save() {
var memo = {fields: {},clicks: []};
document.querySelectorAll("[data-memo]:not([type='checkbox']):not([type='radio'])").forEach(function(item) {
memo.fields[item.id] = item.value;
});
document.querySelectorAll("[data-memo][type='checkbox']:checked,[data-memo][type='radio']:checked").forEach(function(item) {
memo.clicks.push(item.id)
});
localStorage.setItem("memo", JSON.stringify(memo));
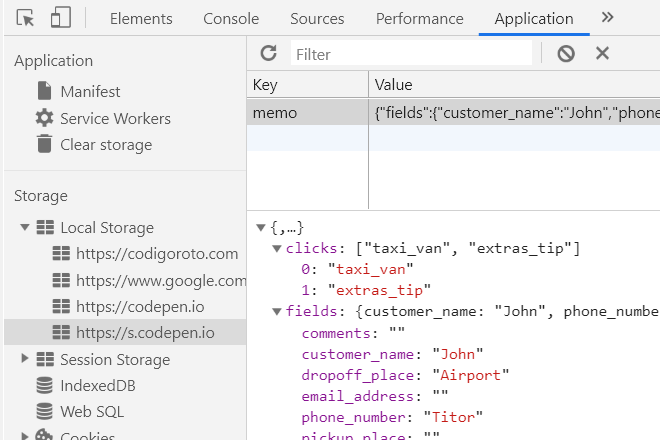
}Si todo va bien, en la pestaña “aplicación” del inspector de Chrome veremos el objeto “stringficado”.
Ahora haremos la función load() para cargar los datos, linkandola a un evento “DOMContentLoaded” del document para que se ejecute lo antes posible.
document.addEventListener("DOMContentLoaded", function() {
load()
});En esta función leeremos y parsearemos el objeto memo y volcamos sus contenidos en los ids correspondientes leídos en el objeto memo.fields, y cambiamos el checked de los elementos citados en el array memo.clicks.
Vamos a aprovechar para utilizar esta misma función (que setea los elementos) para la opción de borrarlos. De esta forma, si le pasamos un parámetro reseteara el elemento, si no hay parámetro, pondrá el valor almacenado en memo. Así, si nos interesa, podemos poner un botón “limpiar” con una llamada la función “load(1)”. En realidad, podemos poner cualquier parametro, lo importante es que exista.
Discriminamos si existe “f” o no con una expresion ternaria.
function load(f) {
var memo = JSON.parse(localStorage.getItem("memo"));
for (x in memo.fields) {
document.getElementById(x).value = (f ? "" : memo.fields[x])
}
for (x in memo.clicks) {
document.getElementById(memo.clicks[x]).checked = f ? false : true;
}
}
function clean() {
load(1)
}Podemos evitar el uso del atributo data-memo (para hacer por ejemplo un snippet que nos valga para cualquier formulario ajeno, o una extension de chrome), sustituyendo el “queryselectorall” por algo así:
("form input:not([type='checkbox']):not([type='radio']),
form select:not([type='checkbox']):not([type='radio']) ")Si algun campo depende de otro, como un select de “localidad” despues del select de “provincia”, podemos usar un settimeout o un evento change asociado al primer select después del primer seteo. Es posible que tengamos que hacer .change() al primer select para activar el evento que rellene el segundo.
Lo encapsulamos todo dentro de un objeto memo_form al estilo del patron de diseño “module” y está vestida para salir de casa.
Podeis juguetear con el tema cambiando valores y refrescando en el siguiente codepen que he preparado:
See the Pen
autosave JS by jorgeblancodeveloper (@jorgeblancodeveloper)
on CodePen.